Serverless
Serverless is a deployment architecture where servers are not explicitly provisioned by the deployer. Code is instead executed based on developer-defined events that are triggered, for example when an HTTP POST request is sent to an API a new line written to a file.
How can code be executed "without" servers?
Servers still exist to execute the code but they are abstracted away from the developer and handled by a compute platform such as Amazon Web Services Lambda or Google Cloud Functions.
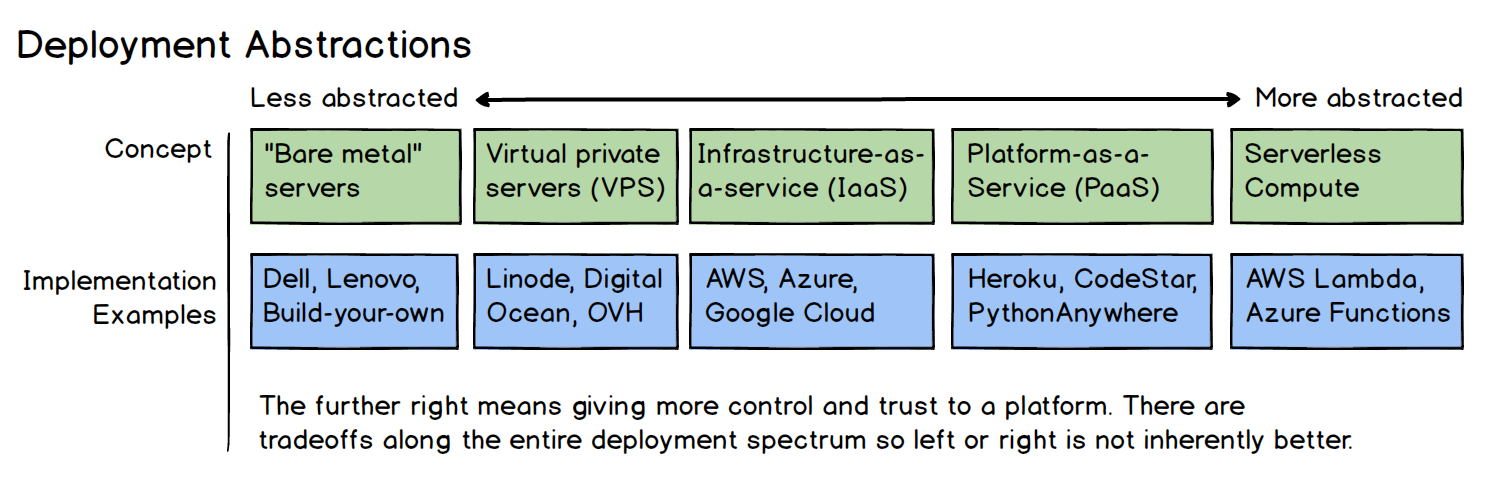
Think about deploying code as a spectrum, where on one side you build your own server from components, hook it up to the internet with a static IP address, connect the IP address to DNS and start serving requests. The hardware, operating system, web server, WSGI server, etc are all completely controlled by you. On the opposite side of the spectrum are serverless compute platforms that take Python code and execute it without you ever touching hardware or even knowing what operating system it runs on.
In between those extremes are levels that remove the need to worry about hardware (virtual private servers), up through removing concerns about web servers (platforms-as-a-service). Where you fall on the spectrum for your deployment will depend on your own situation. Serverless is simply the newest and most extreme of these deployment models so it is up to you as to how much complexity you want to take on with the deployment versus your control over each aspect of the hardware and software.
Serverless implementations
Each major cloud vendor has a serverless compute implementation. These implementations are under significant active development and not all of them have Python support.
-
AWS Lambda is the current leader among serverless compute implementations. It has support for Python 3.x.
-
Azure Functions has second-class citizen support for Python. It's supposed to be possible but kind of hacky at the moment. Polyglot support should be quickly coming to Azure to better compete with AWS Lambda.
-
IBM Bluemix OpenWhisk is based on the Apache OpenWhisk open source project.
-
Webtask.io started as a JavaScript service but now also has a Python runtime as well.
Serverless frameworks
Serverless libraries and frameworks aim to provide reusable code that handles common or tedious tasks, similar to how web frameworks deal with common web development tasks. Some of these frameworks are built for a single service like AWS Lambda, while others attempt to make cross-serverless operations more palatable.
Frameworks for building Python-based applications on serverless services include:
-
Serverless (source code), which is a useful but generically-named library that focuses on deployment and operations for serverless applications.
-
Zappa provides code and tools to make it much easier to build on AWS Lambda and AWS API Gateway than rolling your own on the bare services.
-
Chalice (source code) is built by the AWS team specifically for Python applications.
General serverless resources
Serverless concepts and implementations are still in their early iterations so there are many ideas and good practices yet to be discovered. These resources are the first attempts at figuring out how to structure and operate serverless applications.
-
What's Serverless? is an accessible "first read" for both developers and non-technical audiences alike. It breaks down the differences between what most developers consider serverless and infrastructure-as-a-service (IaaS) offerings.
-
Serverless software covers a range of topics under serverless and how deployments have changed as new options such as PaaS have become widespread.
-
Lessons Learned — A Year Of Going “Fully Serverless” In Production is a retrospective from a small development team that combines a static site with serverless backend code to easily scale their site without an operations staff. They discuss the good and the bad of working in this fashion while generally coming away with a positive experience.
-
From bare metal to Serverless gives some historical detail and background context for how various execution architectures have evolved, from the invention of the web to software-as-a-service, infrastructure-as-a-service to today's newer serverless platforms.
-
Have you shipped anything serious with a “serverless” architecture? provides some great answers by Hacker News developers who are using serverless for large production applications and how they deal with the limitations of the platforms.
-
Serverless cold start war compares startup times of serverless function instances across Google Cloud, AWS and Azure. This is only one way to measure the results the author did a great job presenting the data and elaborating on potential reasons why the results appeared as shown.
-
Serverless Deployments of Python APIs is a wonderful Python-specific article on how to use AWS Lambda, API Gateway and DynamoDB to create and deploy a Python API.
-
Serverless architectures provides a fantastic overview of the subject with a balanced approach that includes the drawbacks seen in current serverless platforms.
-
Why the fuss about serverless? is a wide-ranging post about the history of application development and infrastructure. The timeline is a bit hard to follow but otherwise it's a unique look at why software deployments are moving to serverless-based architectures and the advantages that can provide.
-
Serverless architectures in short lays out some of the initial thoughts behind what the advantages and disadvantages of serverless may be. However, it's early days for serverless so these strengths and weaknesses may change as the architectures and good practices evolve.
-
Building A Serverless Contact Form For Your Static Site uses AWS Lambda, some HTML and JavaScript to add an input form to a static website created by a static site generator.
-
Serverless architectures, five design patterns goes over the four main principles of serverless infrastructure and the five major usage patterns the AWS Lambda team is seeing from initial serverless deployments.
-
Serverless Cost Calculator estimates the amount each serverless platform would charge based on executions, average execution time and memory needed per execution. AWS Lambda, Google Cloud Functions, Azure Functions and IBM OpenWhisk are all included in the results.
Serverless environment comparsions
The "big 3" serverless platforms, AWS Lambda, Azure Functions and Google Cloud Functions have varying degrees of support for Python. AWS Lambda has production-ready support for Python 2 and 3.7, while Azure and Google Cloud have "beta" support with unclear production-worthiness. The following resources are some comparison articles to help you in your decision-making process for which platform to learn. Microsoft Azure Functions vs. Google Cloud Functions vs. AWS Lambda presents an overview of Azure Functions and how they compare to Google Cloud Functions and AWS Lambda.
Serverless vendor lock-in?
There is some concern by organizations and developers about vendor lock-in on serverless platforms. It is unclear if portability is worse for serverless than other infrastructure-as-a-service pieces, but still worth thinking about ahead of time. Why vendor lock-in with serverless isn’t what you think it is is a piece on this topic that recommends using a single vendor for now and for organizations to stop worrying about hedging their bets because it typically makes infrastructure significantly more complex.
What else do you want to learn about serverless and deployments?
Full Stack Python
Updates via Twitter & Facebook.