Using Django & AssemblyAI for More Accurate Twilio Call Transcriptions
Recording phone calls with one or more participants is easy with Twilio's Programmable Voice API, but the speech-to-text accuracy can be poor, especially for transcription of words from niche domains such as healthcare and engineering. AssemblyAI's API for transcription provides much higher accuracy by default and through optional keyword lists. accuracy for recordings.
In this tutorial, we'll record an outbound Twilio call recording to AssemblyAI's API to get significantly more accurate speech-to-text output.
Tutorial Prerequisites
Ensure you have Python 3 installed, because Python 2 reached its end-of-life at the beginning of 2020 and is no longer supported. Preferrably, you should have Python 3.7 or greater installed in your development environment. This tutorial will also use:
We will use the following dependencies to complete this tutorial:
- Django version 3.1.x, where x is the latest security release
- A Twilio account and the Python Twilio helper library version 6.45.2 or newer
- requests version 2.24.0
- An AssemblyAI account, which you can sign up for a free key API access key here
All code in this blog post is available open source under the MIT license on GitHub under the django-accurate-twilio-voice-transcriptions directory of the blog-code-examples repository. Use the source code as you desire for your own projects.
Configuring our development environment
Change into the directory where you keep your Python virtual environments. Create a new virtualenv for this project using the following command.
Start the Django project by creating a new
virtual environment
using the following command. I recommend using a separate directory
such as ~/venvs/ (the tilde is a shortcut for your user's home
directory) so that you always know where all your virtualenvs are
located.
python3 -m venv ~/venvs/djtranscribe
Activate the virtualenv with the activate shell script:
source ~/venvs/djtranscribe/bin/activate
After the above command is executed, the command prompt will
change so that the name of the virtualenv is prepended to the
original command prompt format, so if your prompt is just
$, it will now look like the following:
(djtranscribe) $
Remember, you have to activate your virtualenv in every new terminal window where you want to use dependencies in the virtualenv.
We can now install the Django package into the activated but otherwise empty virtualenv.
pip install django==3.1.3 requests==2.24.0 twilio==6.45.2
Look for output similar to the following to confirm the appropriate packages were installed correctly from PyPI.
(djtranscribe) $ pip install django==3.1.3 requests==2.24.0 twilio=6.45.2
pip install django requests twilio
Collecting django
Downloading Django-3.1.3-py3-none-any.whl (7.8 MB)
|████████████████████████████████| 7.8 MB 2.6 MB/s
Collecting requests
Using cached requests-2.24.0-py2.py3-none-any.whl (61 kB)
Collecting twilio
Downloading twilio-6.47.0.tar.gz (460 kB)
|████████████████████████████████| 460 kB 19.6 MB/s
Collecting sqlparse>=0.2.2
Downloading sqlparse-0.4.1-py3-none-any.whl (42 kB)
|████████████████████████████████| 42 kB 4.8 MB/s
Collecting pytz
Downloading pytz-2020.4-py2.py3-none-any.whl (509 kB)
|████████████████████████████████| 509 kB 31.0 MB/s
Collecting asgiref<4,>=3.2.10
Downloading asgiref-3.3.0-py3-none-any.whl (19 kB)
Collecting chardet<4,>=3.0.2
Using cached chardet-3.0.4-py2.py3-none-any.whl (133 kB)
Collecting idna<3,>=2.5
Using cached idna-2.10-py2.py3-none-any.whl (58 kB)
Collecting certifi>=2017.4.17
Using cached certifi-2020.6.20-py2.py3-none-any.whl (156 kB)
Collecting urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1
Downloading urllib3-1.25.11-py2.py3-none-any.whl (127 kB)
|████████████████████████████████| 127 kB 24.5 MB/s
Collecting six
Using cached six-1.15.0-py2.py3-none-any.whl (10 kB)
Collecting PyJWT>=1.4.2
Using cached PyJWT-1.7.1-py2.py3-none-any.whl (18 kB)
Using legacy 'setup.py install' for twilio, since package 'wheel' is not installed.
Installing collected packages: sqlparse, pytz, asgiref, django, chardet, idna, certifi, urllib3, requests, six, PyJWT, twilio
Running setup.py install for twilio ... done
Successfully installed PyJWT-1.7.1 asgiref-3.3.0 certifi-2020.6.20 chardet-3.0.4 django-3.1.3 idna-2.10 pytz-2020.4 requests-2.24.0 six-1.15.0 sqlparse-0.4.1 twilio-6.47.0 urllib3-1.25.11
We can get started coding the application now that we have all of our required dependencies installed.
Starting our Django project
Let's begin coding our application.
We can use the Django django-admin tool to create
the boilerplate code structure to get our project started.
Change into the directory where you develop your applications. For
example, I typically use /Users/matt/devel/py/ for all of my
Python projects. Then run the following command to start a Django
project named djtranscribe:
django-admin.py startproject djtranscribe
Note that in this tutorial we are using the same name for both the virtualenv and the Django project directory, but they can be different names if you prefer that for organizing your own projects.
The django-admin command creates a directory named djtranscribe
along with several subdirectories that you should be familiar with
if you have previously worked with Django.
Change directories into the new project.
cd djtranscribe
Create a new Django app within djtranscribe named caller.
python manage.py startapp caller
Django will generate a new folder named caller in the project.
We should update the URLs so the app is accessible before we write
our views.py code.
Open djtranscribe/djtranscribe/urls.py. Add the highlighted
lines so that URL resolver will check the caller app
for additional routes to match with URLs that are requested of
this Django application.
# djtranscribe/djtranscribe/urls.py
from django.conf.urls import include
from django.contrib import admin
from django.urls import path
urlpatterns = [
path('', include('caller.urls')),
path('admin/', admin.site.urls),
]
Save djtranscribe/djtranscribe/urls.py and open
djtranscribe/djtranscribe/settings.py.
Add the caller app to settings.py by inserting
the highlighted line:
# djtranscribe/djtranscribe/settings.py
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'caller',
]
Make sure you change the default DEBUG and SECRET_KEY
values in settings.py before you deploy any code to production. Secure
your app properly with the information from the Django
production deployment checklist
so that you do not add your project to the list of hacked applications
on the web.
Save and close settings.py.
Next change into the djtranscribe/caller directory. Create
a new file named urls.py to contain routes for the caller app.
Add all of these lines to the empty djtranscribe/caller/urls.py
file.
# djtranscribe/caller/urls.py
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'', views.index, name="index"),
]
Save djtranscribe/caller/urls.py. Open
djtranscribe/caller/views.py to add the
following two highlighted lines.
# djtranscribe/caller/views.py
from django.http import HttpResponse
def index(request):
return HttpResponse('Hello, world!', 200)
We can test out that this simple boilerplate response is
correct before we start adding the meat of the functionality to
the project. Change into the base directory of your Django project
where the manage.py file is located. Execute the development
server with the following command:
python manage.py runserver
The Django development server should start up with no issues other than an unapplied migrations warning.
Watching for file changes with StatReloader
Performing system checks...
System check identified no issues (0 silenced).
November 15, 2020 - 14:07:03
Django version 3.1.3, using settings 'djtranscribe.settings'
Starting development server at http://127.0.0.1:8000/
Quit the server with CONTROL-C.
Open a web browser and go to localhost:8000.
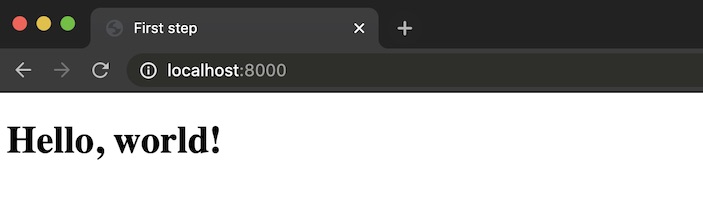
You should see 'Hello, world!' rendered in the browser. That means everything is working properly so far and we can now add the dialing, recording and transcribing capabilities to our Django project.
Adding Twilio to the Django project
Time to add Twilio's Voice API into the mix so we can dial a phone call from our Django project and make a recording out of it.
Start by opening up djtranscribe/djtranscribe/settings.py
and modifying it with the following highlighted import os
line:
# djtranscribe/djtranscribe/settings.py
import os
from pathlib import Path
# Build paths inside the project like this: BASE_DIR / 'subdir'.
BASE_DIR = Path(__file__).resolve().parent.parent
Then at the bottom of the settings.py file, add the
following highlighted lines, which will be settings that are pulled from
environment variables we will configure later.
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/3.1/howto/static-files/
STATIC_URL = '/static/'
BASE_URL = os.getenv("BASE_URL")
TWIML_INSTRUCTIONS_URL = "{}/record/".format(BASE_URL)
TWILIO_PHONE_NUMBER = os.getenv("TWILIO_PHONE_NUMBER")
Save settings.py and change into the caller Django app directory.
Update djtranscribe/caller/urls.py with the the following new
code:
# djtranscribe/caller/urls.py
from django.conf.urls import url
from . import views
urlpatterns = [
url(r'dial/(\d+)/$', views.dial, name="dial"),
url(r'record/$', views.record_twiml, name="record-twiml"),
url(r'get-recording-url/([A-Za-z0-9]+)/$', views.get_recording_url,
name='recording-url'),
]
Next, open djtranscribe/views.py and update it with the following
code, replacing what already exists within the file:
# djtranscribe/caller/views.py
from django.conf import settings
from django.http import HttpResponse
from django.views.decorators.csrf import csrf_exempt
from twilio.rest import Client
from twilio.twiml.voice_response import VoiceResponse
def dial(request, phone_number):
"""Dials an outbound phone call to the number in the URL. Just
as a heads up you will never want to leave a URL like this exposed
without authentication and further phone number format verification.
phone_number should be just the digits with the country code first,
for example 14155559812."""
# pulls credentials from environment variables
twilio_client = Client()
call = twilio_client.calls.create(
to='+{}'.format(phone_number),
from_=settings.TWILIO_PHONE_NUMBER,
url=settings.TWIML_INSTRUCTIONS_URL,
)
print(call.sid)
return HttpResponse("dialing +{}. call SID is: {}".format(
phone_number, call.sid))
@csrf_exempt
def record_twiml(request):
"""Returns TwiML which prompts the caller to record a message"""
# Start our TwiML response
response = VoiceResponse()
# Use <Say> to give the caller some instructions
response.say('Ahoy! Call recording starts now.')
# Use <Record> to record the caller's message
response.record()
# End the call with <Hangup>
response.hangup()
return HttpResponse(str(response), content_type='application/xml')
def get_recording_url(request, call_sid):
"""Returns an HttpResponse with plain text of the link to one or more
recordings from the specified Call SID."""
# pulls credentials from environment variables
twilio_client = Client()
recording_urls = ""
call = twilio_client.calls.get(call_sid)
for r in call.recordings.list():
recording_urls="\n".join([recording_urls, "".join(['https://api.twilio.com', r.uri])])
return HttpResponse(str(recording_urls), 200)
Each of the above view functions performs one of the steps needed to
create a call recording of a phone call dialed by Twilio, and then
retrieve it as a file. dial programmatically initiates the outbound
call, record_twiml returns instructions to play a message that the
call is being recorded, records it, and then hangs up when the call
is done. get_recording_url only returns the URL location of the
recorded phone call so that in the next step we can send the file over
to AssemblyAI.
Our Django project modifications are done. Next, we need to use two services, Twilio and Ngrok, to enable some of the machine to happen of phone calling and running the application from our local machine.
Twilio credentials and environment variables
Sign up for Twilio or
log into your existing account.
Once you get to the Twilio Console,
you can obtain your TWILIO_ACCOUNT_SID and TWILIO_AUTH_TOKEN on the
right side of the page:
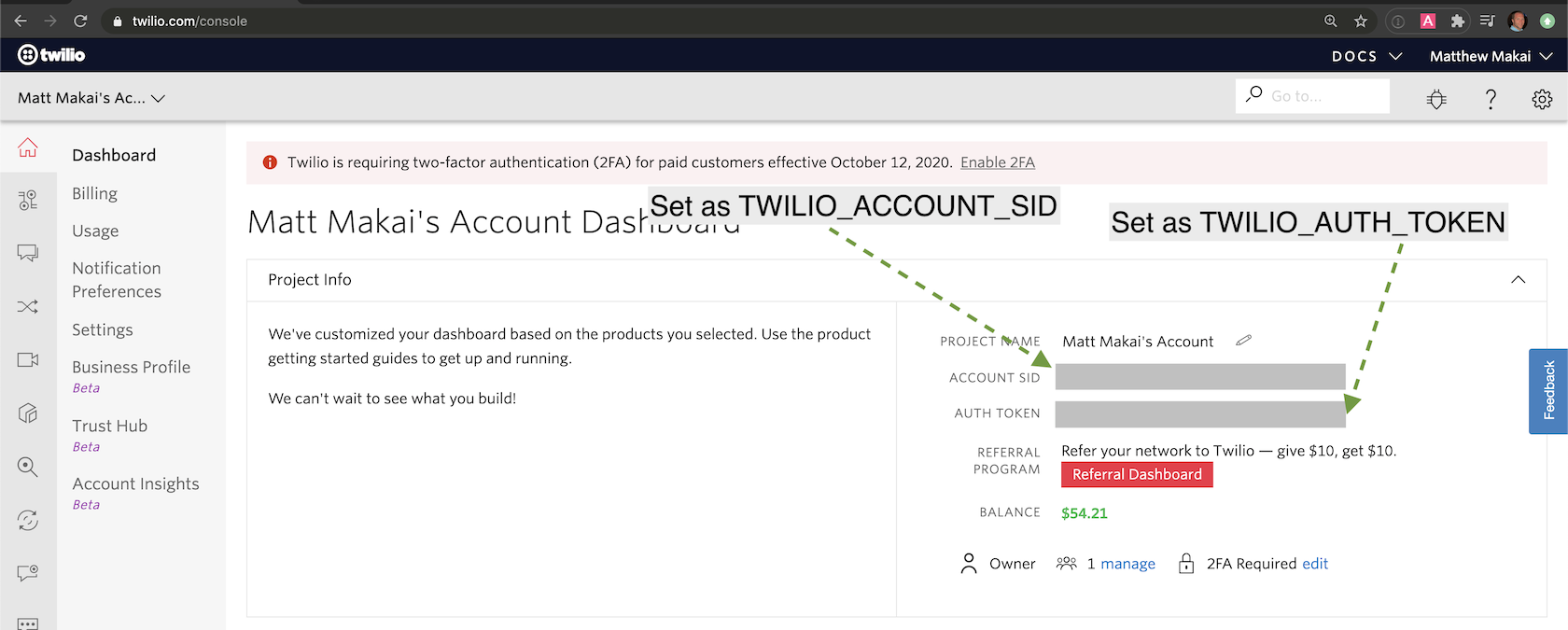
When you sign up you should have a phone number assigned to your account. You can use that or purchase a new phone number to use.
Set three environment variables with the names TWILIO_ACCOUNT_SID,
TWILIO_AUTH_TOKEN, and TWILIO_PHONE_NUMBER using the export command
in your terminal. Make sure to replace the values with your own Account SID,
Auth Token and Twilio phone number.
export TWILIO_ACCOUNT_SID=xxxxxxxxxxxxx # found in twilio.com/console
export TWILIO_AUTH_TOKEN=yyyyyyyyyyyyyy # found in twilio.com/console
export TWILIO_PHONE_NUMBER=+17166382453 # replace with your Twilio number
Note that you must use the export command in every command line window
that you want this key to be accessible. The scripts we are writing will
not be able to access the Twilio APIs if you do not have the tokens exported
in the environment where you are running the script.
There is one more environment variable to set before we can run app.py.
We need to use Ngrok as a localhost tunnel so that Twilio's webhook can
send an HTTP POST request to our Django application running on
our local development environment.
Run Ngrok in a new terminal window, because you will need to keep it running while we run our other Python code:
./ngrok http 8000
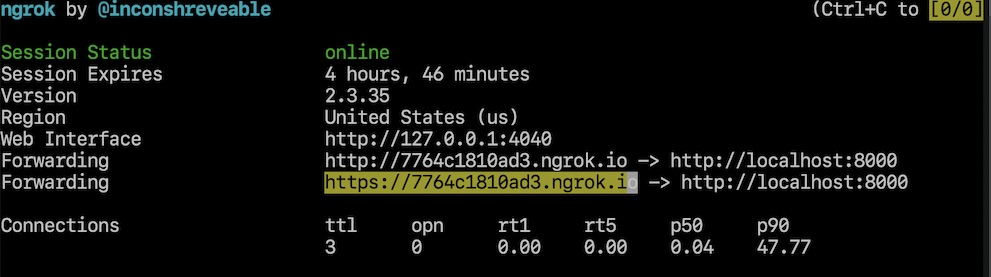
Copy the HTTPS version of the "Forwarding" URL and set the BASE_URL
environment variable value to it. For example, in this screenshot you
would set BASE_URL to https://7764c1810ad3.ngrok.io using the
following command:
export BASE_URL=https://7764c1810ad3.ngrok.io # use your ngrok URL, or domain. no trailing slash
We also need to update djtranscribe/djtranscribe/settings.py's
ALLOWED_HOSTS list to include the Ngrok Forwarding URL otherwise
the webhook from Twilio asking for instructions
on how to handle the phone call will fail. Open the settings.py
file and update the ALLOWED_HOSTS with your Ngrok Forwarding
hostname list the following:
# SECURITY WARNING: keep the secret key used in production secret!
SECRET_KEY = os.getenv('SECRET_KEY', 'development key')
# SECURITY WARNING: don't run with debug turned on in production!
DEBUG = True
ALLOWED_HOSTS = ['7764c1810ad3.ngrok.io','127.0.0.1','localhost']
# Application definition
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'caller',
]
Okay, we can finally re-run our Django web app. Ensure Ngrok is still
running in a different window, your virtualenv is active and that in this
terminal you have your four environment variables set, then run the
runserver command in the root project directory where manage.py
is located:
python manage.py runserver
Let's make our phone ring by testing the application.
Testing Twilio Programmable Voice Recording
We can test our application by going to localhost on port 8000. Go to this URL in your web browser, replacing the "14155551234" with the phone number you want to call, where the person on the line will be recorded: http://localhost:8000/dial/14155551234.
That number should now receive a phone call from your Twilio number. Pick up, record a message that you want to use to test the transcription, and then hang up.
If you get an error, make sure all of your environment variables are set. You can check the values by using the echo command like this:
echo $BASE_URL
When the call is over, copy the call SID show on the web page so that we can use it to look up where the recording audio file is stored.

Go to "localhost:8000/get-recording-url/" with the call SID at the end. For example, "localhost:8000/get-recording-url/CAda3f2f49ff4e8ef2be6b726edb998c92".

Copy the entire output except for the ".json" at the end, then paste it into the web browser's URL bar, prepended with "api.twilio.com". For example, "https://api.twilio.com/2010-04-01/Accounts/ACe3737affa0d2e17561ad44c9d190e70c/Recordings/RE3b42cf470bef829c3680ded961a09300". This will bring up the recording. Copy the entire URL and we will use it as input into the AssemblyAI service.
Transcribing with the AssemblyAI API
We can now use the AssemblyAI API for speech-to-text transcription on the call recording that was just made.
Sign up for an AssemblyAI account and log in to the AssemblyAI dashboard, then copy "Your API token" as shown in this screenshot:
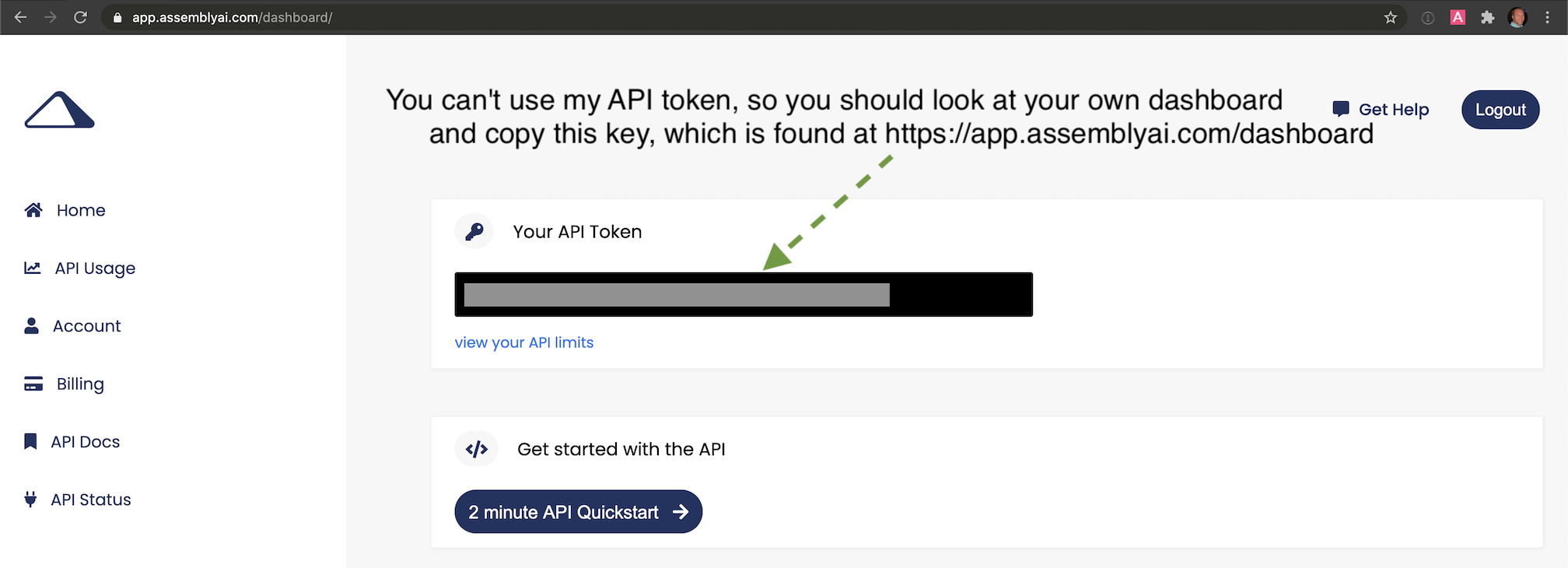
We need to export our AssemblyAI API key as an environment variable so that our Python application can use it to authenticate with their API. We also need to pass the publicly-accessible URL for the recording, so we'll set that as an environment variable as well.
# make sure to replace this URL with the one for your recording
export ASSEMBLYAI_KEY=your-api-key-here
export RECORDING_URL=https://api.twilio.com/2010-04-01/Accounts/ACe3737affa0d2e17561ad44c9d190e70c/Recordings/RE3b42cf470bef829c3680ded961a09300
Create a new file named transcribe.py and write the following code in it:
import os
import requests
endpoint = "https://api.assemblyai.com/v2/transcript"
json = {
"audio_url": os.getenv("RECORDING_URL")
}
headers = {
"authorization": os.getenv("ASSEMBLYAI_KEY"),
"content-type": "application/json"
}
response = requests.post(endpoint, json=json, headers=headers)
print(response.json())
The above code calls the AssemblyAI transcription service using the secret key and passes it the URL with the file recording. The script prints out the JSON response from the service, which will contain a transcription ID that we'll use to access the results after they finish processing.
Run the script using the python command:
python transcribe.py
You will get back some JSON as output, similar what you see here:
{'audio_end_at': None, 'acoustic_model': 'assemblyai_default', 'text': None, 'audio_url': 'https://api.twilio.com/2010-04-01/Accounts/ACe3737affa0d2e17561ad44c9d190e70c/Recordings/RE3b42cf470bef829c3680ded961a09300', 'speed_boost': False, 'language_model': 'assemblyai_default', 'redact_pii': False, 'confidence': None, 'webhook_status_code': None, 'id': 'zibe9vwmx-82ce-476c-85a7-e82c09c67daf', 'status': 'queued',
'boost_param': None, 'words': None, 'format_text': True, 'webhook_url': None, 'punctuate': True, 'utterances': None, 'audio_duration': None, 'auto_highlights': False, 'word_boost': [], 'dual_channel': None, 'audio_start_from': None}
Find the value contained with the id field of the JSON response. We need
that value to look up the final result of our transcription. Copy the
transcription ID and set it as an environment variable to use as input by
the final script:
# replace with what's found within `id` from the JSON response
export TRANSCRIPTION_ID=aksd19vwmx-82ce-476c-85a7-e82c09c67daf
We just need a little more Python that looks up the result and we'll be all done.
Retrieve the AssemblyAI Transcription
AssemblyAI will be busy transcribing the recording. Depending on the size of the file it can take anywhere from a few seconds to a few minutes for the job to complete. We can use the following code to see if the job is still in progress or it has completed. If the transcription is done it will print the results to the terminal.
Create a new file named print_transcription.py with the following code:
import os
import requests
endpoint = "https://api.assemblyai.com/v2/transcript/{}".format(os.getenv("TRANSCRIPTION_ID"))
headers = {
"authorization": os.getenv("ASSEMBLYAI_KEY"),
}
response = requests.get(endpoint, headers=headers)
print(response.json())
print("\n\n")
print(response.json()['text'])
The code above in print_transcription.py is very similar to the code
in the previous transcribe.py source file. imports os (operating system)
from the Python standard library, as we did in the previous two files,
to obtain the TRANSCRIPTION_ID and ASSEMBLYAI_KEY environment variable
values.
The endpoint is the AssemblyAI API endpoint for retrieving
transcriptions. We set the appropriate authorization header and
make the API call using the requests.get function. We then print
out the JSON response as well as just the text that was transcribed.
Time to test out this third file. Execute the following command in the terminal:
python print_transcription.py
Your output will be different based on your recording but you should see a result in the terminal similar to the following:
{'audio_end_at': None, 'acoustic_model': 'assemblyai_default', 'auto_highlights_result': None, 'text': 'An object relational mapper is a code library that automates the transfer of data stored in a relational database tables into objects that are more commonly used in application. Code or MS provide a high level abstraction upon a relational database that allows the developer to write Python code. Instead of sequel to create read update and delete data and schemas in their database developers can use the programming language that they are comfortable with comfortable to work with the database instead of writing sequel statements or short procedures.', 'audio_url': 'https://api.twilio.com/2010-04-01/Accounts/ACe3737affa0d2e17561ad44c9d190e70c/Recordings/RE3b42cf470bef829c3680ded961a09300', 'speed_boost': False, 'language_model': 'assemblyai_default', 'id': 'zibe9vwmx-82ce-476c-85a7-e82c09c67daf', 'confidence': 0.931797752808989, 'webhook_status_code': None, 'status': 'completed', 'boost_param': None, 'redact_pii': False, 'words': [{'text': 'An', 'confidence': 1.0, 'end': 90, 'start': 0}, {'text': 'object', 'confidence': 0.94, 'end': 570, 'start': 210}, {'text': 'relational', 'confidence': 0.89, 'end': 1080, 'start': 510}, {'text': 'mapper', 'confidence': 0.97, 'end': 1380, 'start': 1020}, {'text': 'is', 'confidence': 0.88, 'end': 1560, 'start': 1350}, {'text': 'a', 'confidence': 0.99, 'end': 1620, 'start': 1500}, {'text': 'code', 'confidence': 0.93, 'end': 1920, 'start': 1620}, {'text': 'library', 'confidence': 0.94, 'end': 2250, 'start': 1860}, {'text': 'that', 'confidence': 0.99, 'end': 2490, 'start': 2220}, {'text': 'automates', 'confidence': 0.93, 'end': 2940, 'start': 2430}, {'text': 'the', 'confidence': 0.95, 'end': 3150, 'start': 2910}, {'text': 'transfer', 'confidence': 0.98, 'end': 3510, 'start': 3090}, {'text': 'of', 'confidence':
0.99, 'end': 3660, 'start': 3480}, {'text': 'data', 'confidence': 0.84, 'end': 3960, 'start': 3630}, {'text': 'stored', 'confidence': 0.89, 'end': 4350, 'start': 3900}, {'text': 'in', 'confidence': 0.98, 'end': 4500, 'start': 4290}, {'text': 'a', 'confidence': 0.85, 'end': 4560, 'start': 4440}, {'text': 'relational', 'confidence': 0.87, 'end': 5580, 'start': 4500}, {'text': 'database', 'confidence': 0.92, 'end':
6030, 'start': 5520}, {'text': 'tables', 'confidence': 0.93, 'end': 6330, 'start': 5970}, {'text': 'into', 'confidence': 0.92, 'end': 7130, 'start': 6560}, {'text': 'objects', 'confidence': 0.96, 'end': 7490, 'start': 7100}, {'text': 'that', 'confidence': 0.97, 'end': 7700, 'start': 7430}, {'text': 'are', 'confidence': 0.9, 'end': 7850, 'start': 7640}, {'text': 'more', 'confidence': 0.97, 'end': 8030, 'start': 7790}, {'text': 'commonly', 'confidence': 0.92, 'end': 8480, 'start': 7970}, {'text': 'used', 'confidence': 0.86, 'end': 8750, 'start': 8420}, {'text': 'in', 'confidence': 0.94, 'end': 9050, 'start': 8840}, {'text': 'application.', 'confidence': 0.98, 'end': 9860, 'start': 9110}, {'text': 'Code', 'confidence': 0.93, 'end': 10040, 'start': 9830}, {'text': 'or', 'confidence': 1.0, 'end': 11210, 'start': 10220}, {'text': 'MS', 'confidence': 0.83, 'end': 11480, 'start': 11180}, {'text': 'provide', 'confidence': 0.94, 'end': 11870, 'start': 11510}, {'text': 'a', 'confidence': 1.0, 'end': 11960, 'start': 11840}, {'text': 'high', 'confidence': 1.0, 'end': 12200, 'start': 11930}, {'text': 'level', 'confidence': 0.94, 'end': 12440, 'start': 12170}, {'text': 'abstraction', 'confidence': 0.95, 'end': 12980, 'start': 12410}, {'text':
'upon', 'confidence': 0.94, 'end': 13220, 'start': 12950}, {'text': 'a', 'confidence': 1.0, 'end': 13280, 'start': 13160}, {'text': 'relational', 'confidence': 0.94, 'end': 13820, 'start': 13280}, {'text': 'database', 'confidence': 0.95, 'end': 14210, 'start': 13790}, {'text': 'that', 'confidence': 0.96, 'end': 14420, 'start': 14150}, {'text': 'allows', 'confidence': 0.99, 'end': 14720, 'start': 14360}, {'text':
'the', 'confidence': 0.56, 'end': 14870, 'start': 14690}, {'text': 'developer', 'confidence': 0.98, 'end': 15290, 'start': 14810}, {'text': 'to', 'confidence': 0.94, 'end': 15410, 'start': 15230}, {'text': 'write', 'confidence': 0.96, 'end': 15680, 'start': 15380}, {'text': 'Python', 'confidence': 0.94, 'end': 16070, 'start': 15620}, {'text': 'code.', 'confidence': 0.98, 'end': 16310, 'start': 16070}, {'text': 'Instead', 'confidence': 0.97, 'end': 17160, 'start': 16500}, {'text': 'of', 'confidence': 0.93, 'end': 17340, 'start': 17130}, {'text': 'sequel', 'confidence': 0.86, 'end': 17820, 'start': 17280}, {'text': 'to', 'confidence': 0.91, 'end': 18090, 'start': 17880}, {'text': 'create', 'confidence': 0.89, 'end': 18450, 'start': 18090}, {'text': 'read', 'confidence': 0.88, 'end': 18840, 'start': 18480}, {'text': 'update', 'confidence': 0.92, 'end': 19290, 'start': 18870}, {'text': 'and', 'confidence': 0.94, 'end': 19590, 'start': 19230}, {'text': 'delete', 'confidence': 0.89, 'end': 19920, 'start': 19530}, {'text': 'data',
'confidence': 0.95, 'end': 20190, 'start': 19890}, {'text': 'and', 'confidence': 0.92, 'end': 20490, 'start': 20250}, {'text': 'schemas', 'confidence': 0.86, 'end': 21000, 'start': 20430}, {'text': 'in', 'confidence': 0.94, 'end': 21210, 'start': 21000}, {'text': 'their', 'confidence': 0.98, 'end': 21510, 'start': 21150}, {'text': 'database', 'confidence': 0.97, 'end': 21900, 'start': 21450}, {'text': 'developers', 'confidence': 0.83, 'end': 23200, 'start': 22420}, {'text': 'can', 'confidence': 0.95, 'end': 23440, 'start': 23200}, {'text': 'use', 'confidence': 0.97, 'end': 23650, 'start': 23410}, {'text': 'the', 'confidence': 0.99, 'end': 23890, 'start': 23590}, {'text': 'programming', 'confidence': 0.97, 'end': 24370, 'start': 23830}, {'text': 'language', 'confidence': 1.0, 'end': 24700, 'start': 24310}, {'text': 'that', 'confidence': 1.0, 'end': 24880, 'start': 24640}, {'text': 'they', 'confidence': 0.99, 'end': 25060, 'start': 24820}, {'text': 'are', 'confidence': 0.85, 'end': 25210, 'start': 25000}, {'text': 'comfortable', 'confidence': 0.92, 'end': 25780, 'start': 25180}, {'text': 'with', 'confidence': 1.0, 'end': 25960, 'start': 25720}, {'text': 'comfortable', 'confidence': 0.94, 'end': 29090, 'start': 28090}, {'text': 'to', 'confidence': 0.84, 'end': 29840, 'start': 29180}, {'text': 'work', 'confidence': 0.95, 'end': 30050, 'start': 29780}, {'text': 'with', 'confidence': 0.98, 'end': 30290, 'start': 30020}, {'text': 'the', 'confidence': 0.69, 'end': 30440, 'start': 30230}, {'text': 'database', 'confidence': 0.98, 'end': 30860, 'start': 30380}, {'text': 'instead', 'confidence': 1.0, 'end': 32780, 'start': 31780}, {'text': 'of', 'confidence': 0.98, 'end': 32900, 'start': 32720}, {'text': 'writing', 'confidence': 0.87, 'end': 33320, 'start': 32870}, {'text': 'sequel', 'confidence': 0.88, 'end': 33860, 'start': 33290}, {'text': 'statements', 'confidence': 0.95, 'end': 34310, 'start': 33800}, {'text': 'or', 'confidence': 0.9, 'end': 34460, 'start': 34250}, {'text': 'short', 'confidence': 0.9, 'end': 34790, 'start': 34430}, {'text': 'procedures.', 'confidence': 0.98, 'end': 35270, 'start': 34760}], 'format_text': True, 'webhook_url': None, 'punctuate': True, 'utterances': None, 'audio_duration': 36.288, 'auto_highlights': False, 'word_boost': [],
'dual_channel': None, 'audio_start_from': None}
An object relational mapper is a code library that automates the transfer of data stored in a relational database tables into objects that are more commonly used in application. Code or MS provide a high level abstraction upon a relational database that allows the developer to write Python code. Instead of sequel to create read update and delete data and schemas in their database developers can use the programming language that they are comfortable with comfortable to work with the database instead of writing sequel statements or short procedures.
That's a lot of output. The first part contains the results of the transcription and the confidence in the accuracy of each word transcribed. The second part is just the plain text output from the transcription.
You can take this now take this base code and add it to any application that needs high quality text-to-speech transcription. If the results aren't quite good enough for you yet, check out this tutorial on boosting accuracy for keywords or phrases.
Additional resources
We just finished building a highly accurate transcription application for recordings.
Next, try out some of these other related Django tutorials:
- Using Sentry to Handle Python Exceptions in Django Projects
- Tracking Daily User Data in Django with django-user-visit
- How to Quickly Use Bootstrap 4 in a Django Template with a CDN
Questions? Let me know via a GitHub issue ticket on the Full Stack Python repository, on Twitter @fullstackpython or @mattmakai. See something wrong with this post? Fork this page's source on GitHub and submit a pull request.
